Avez-vous déjà avis une dégradation des performances of vos modèles d'IA ?
Développer un modèle d’IA implique, en imagerie médicale comme dans tout autre domaine, un processus complet comportant plusieurs étapes critiques. Cela commence par collecte et préparation des données, en s'assurant que les données sont propres, pertinentes et adaptées à l'analyse. Ensuite, la phase de conception implique création de l'architecture initiale du modèle et sélection des algorithmes appropriés. De nombreuses expériences et validations sont menées pour tester différentes configurations et approches. Ces expériences permettent d'affiner le modèle, d'optimiser ses paramètres et d'améliorer sa précision et ses performances. Ce processus itératif se poursuit jusqu'à ce que le plus performant soit atteint. AI le modèle est identifié. Ce modèle est ensuite sélectionné pour être intégré dans une solution finale, prête à être déployée et utilisée pour des applications pratiques.
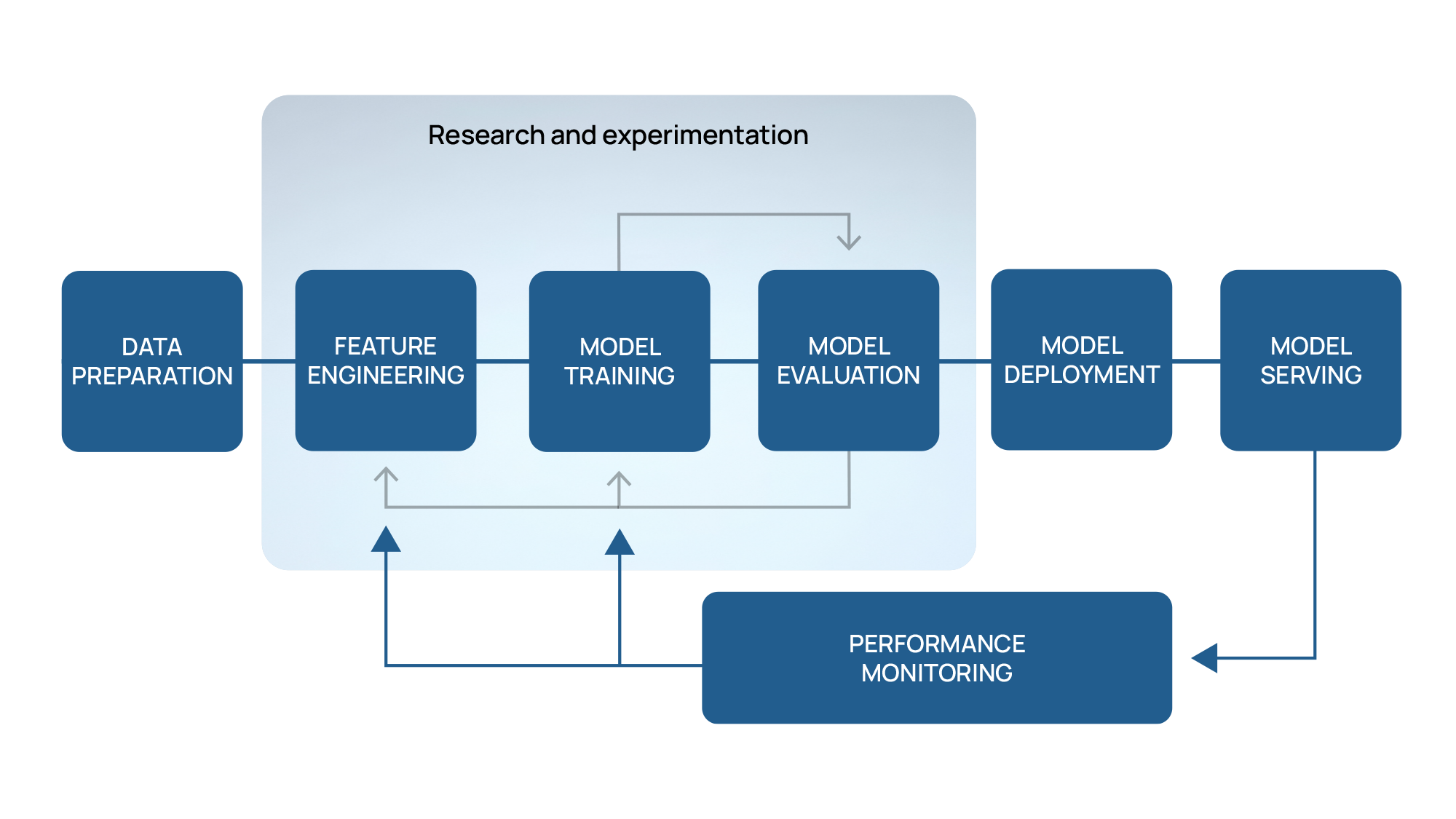
Figuree 1 - Flux de travail de développement de modèles d'IA
Cependant, le flux de travail de l'IA ne doit pas se terminer une fois le modèle déployé en production. Au fil du temps, les modèles en production subiront une dégradation de leur pouvoir prédictif, un phénomène connu sous le nom de dérive du modèle. Ce déclin résulte des changements continus dans les données utilisées comme données d’entrée pour les modèles. Des exemples de ces changements dans le domaine de l’imagerie médicale peuvent résulter de nouveaux développements dans les technologies d’imagerie ou de modifications dans les protocoles d’acquisition. Par conséquent, les modèles rencontrent des données sur lesquelles ils doivent être formés, ce qui entraîne une diminution potentielle de la précision de leurs prédictions médicales.
Il est donc essentiel de surveiller en permanence les performances des modèles d’IA pour identifier ces problèmes et développer des stratégies pour les atténuer. La dérive du modèle peut être globalement classée en deux types principaux :
Dérive de concept
Une dérive conceptuelle se produit lorsque les modèles appris par le modèle à partir des données d'entraînement/de test changent, conduisant à de nouveaux modèles invisibles dans les données de production. Par exemple, dans le domaine de l'imagerie médicale, cela peut se produire avec l'émergence de nouvelles maladies ou de nouveaux traitements. Au début de la pandémie de COVID19, les modèles d'IA initialement formés pour identifier les anomalies dans les radiographies thoraciques n'étaient pas en mesure de détecter les anomalies liées au COVID19. Il s'agit d'un exemple clair de dérive conceptuelle.
Covariable ou dérive des données
Ce type de dérive se produit lorsque la distribution des caractéristiques dans les données d’entraînement/de test diffère de celle des données de prédiction. La dérive des covariables peut être divisée en dérive d’entrée et dérive de sortie.
Dérive d'entrée
Cela implique des modifications dans les données d’entrée, telles que des modifications dans médical images ou caractéristiques causées par des modifications dans les scanners. Cela peut affecter les modèles d’IA, car les modèles formés sur des images provenant de scanners actuels pourraient ne pas fonctionner correctement avec les images provenant de scanners futurs, si de nouvelles techniques de reconstruction d’images ou de nouveaux contrastes sont utilisés.
Dérive de sortie
Cela se produit lorsqu'il y a des changements dans la distribution des résultats du modèle, qui peuvent résulter de modifications des directives de reporting.
Un exemple de ce problème pourrait être un modèle d'imagerie médicale formé pour classer les stades des tumeurs primaires dans le cancer du poumon. Supposons que le modèle ait été développé à l'aide de données classées selon la 7e édition de la classification TNM du cancer du poumon. Si les nouvelles données en production respectent les directives de la 8e édition, la distribution de sortie du modèle sera modifiée. Ce changement peut entraîner une baisse des performances, car le modèle peut ne plus être conforme aux normes mises à jour, ce qui peut entraîner des inexactitudes dans la stadification de la tumeur primaire.

Figuree 2 - Concept et dérive des données
Détecter la dérive du modèle
Il existe deux stratégies principales pour détecter la dérive du modèle, en fonction de la disponibilité de la vérité terrain (valeurs réelles) :
Détection de dérive supervisée
Lorsque la vérité fondamentale devient disponible quelque temps après les prédictions du modèle, elle peut être utilisée pour comparer ces prédictions en utilisant les mêmes stratégies de validation que celles utilisées lors du développement et de la sélection du modèle. Si les mesures obtenues en production sont nettement moins bonnes que celles de la phase de validation, le modèle connaît une dérive.
Détection de dérive non supervisée
Une approche plus ambitieuse est nécessaire dans les scénarios où la vérité fondamentale n’est pas disponibleNous nous concentrerons ici sur ce scénario, qui est le plus courant dans les applications du monde réel.
Plusieurs méthodes pour détecter la dérive de manière non supervisée varient en fonction du type de données, de l’algorithme et du fait qu’ils utilisent des prédictions d’entrée ou de sortie.
- Approches basées sur des tests statistiques
L’une des méthodes les plus utilisées implique des tests statistiques qui comparent les distributions de données.Ces tests fonctionnent sous l’hypothèse que si des disparités statistiques significatives existent entre les données de référence (utilisées pour la formation et les tests) et les données d’analyse (utilisées en production), nous ne pouvons pas supposer que le modèle produira des résultats similaires dans les deux ensembles de données.
En règle générale, ces tests comparent des variables numériques ou catégorielles en calculant certaines mesures pour évaluer la divergence entre les deux ensembles de données. Si ces différences dépassent un seuil spécifié, l'algorithme considère qu'il y a une dérive. Voici quelques exemples de ces méthodes : Test de Kolmogorov-Smirnov à deux échantillons, Test du chi carré, Distance de Wassertein or Divergence Kullback-Leibler.
- Approches basées sur la classification
Une autre approche implique des algorithmes d’IA pour détecter les différences entre les ensembles de données, en particulier entre les ensembles de données de référence et de production. Le classificateur de domaine en est un exemple. Dans cette méthode, un modèle est formé à l'aide d'un sous-ensemble de données de référence et de production. Si le modèle peut déterminer avec précision si les nouveaux points de données appartiennent au domaine de référence ou de production, il indique des différences significatives entre les ensembles de données. Cela implique que les données en production sont différentes de l'ensemble de données de référence, ce qui affecte potentiellement les performances prédictives du modèle.
- Approches basées sur l'incertitude
D'autres méthodes exploitent l'incertitude du modèle en production pour détecter les dérivesL'incertitude du modèle mesure le degré de confiance du modèle dans ses prédictions et peut être surveillée pendant la production. Si le modèle commence à montrer une plus grande incertitude dans ses prédictions, cela pourrait indiquer que des caractéristiques spécifiques des données de production réduisent la confiance du modèle. Cela peut signaler une baisse potentielle des performances.
Suivi des performances dans Quibim
In Quibim, nous reconnaissons l’importance de surveiller les performances de nos modèles en production et de détecter les diminutions de précision prédictive le plus tôt possible. Nous recherchons continuellement les meilleures approches pour chacun de nos modèles en production.
Dans nos produits, nous intégrons un système de surveillance comme stratégie de surveillance post-commercialisation, afin de détecter, le plus tôt possible, les sources potentielles de dérive et de les minimiser, améliorant ainsi l'expérience client. nous sommes à l'avant-garde du développement d'outils permettant de surveiller les modèles de production à travers Projets financés par l'Europe comme ProCAncer-I et RadioVal. Dans ces projets, nous développons des outils qui intègrent plusieurs méthodes de détection de dérive dans les modèles d'IA en production pour différents cas d'utilisation.
Nous utilisons des méthodes basées sur des tests statistiques pour détecter les changements dans la distribution des données d'entréePlus précisément, nous développons des solutions pour identifier les différences dans les caractéristiques radiomiques extraites au niveau d’un organe ou d’une lésion dans différents cas d’utilisation.
In RadioVal, les caractéristiques radiomiques sont utilisées pour prédire la réponse des patients à la chimiothérapie néoadjuvante. De même, dans ProCAncer-I, Des modèles prédictifs basés sur des caractéristiques radiomiques sont en cours de développement pour le diagnostic précoce, l'attribution du traitement et la prédiction de la réponse, ainsi que le suivi des patients atteints d'un cancer de la prostate. En partant de l'hypothèse que les distributions de ces caractéristiques devraient rester cohérentes entre les données de référence et de production, si des incohérences sont détectées, cela peut indiquer que le modèle fait des prédictions sur des données différentes de celles sur lesquelles il a été formé et validé, ce qui pourrait affecter ses performances.
Une approche complémentaire a été développée pour cibler la dérive des données d’entrée. Dans ce deuxième scénario, nous nous concentrons directement sur les données d’imagerie. Dans ProCAncer-I, nous utilisons des approches qui impliquent l'utilisation d'auto-encodeurs, des algorithmes d'IA qui peuvent être utilisés pour extraire des caractéristiques profondes des images.Ces caractéristiques profondes, représentées sous forme de valeurs numériques, sont utilisées par les modèles d'IA pour effectuer des tâches telles que la reconstruction d'images. Cependant, elles peuvent également être utilisées pour comparer les distributions de données. Si les caractéristiques profondes des données d'entraînement et de test sont significativement différentes de celles extraites des données de production, cela peut indiquer une dérive du modèle.
Enfin, des nous incorporons des méthodes supplémentaires pour détecter la dérive des cibles dans nos modèles de classification. Ces méthodes comparent la distribution des résultats du modèle entre les données de référence et les données de production en utilisant également des tests statistiques. Si des changements significatifs sont détectés, une analyse plus approfondie des données est nécessaire pour exclure la possibilité d'une diminution des performances de classification du modèle en production.
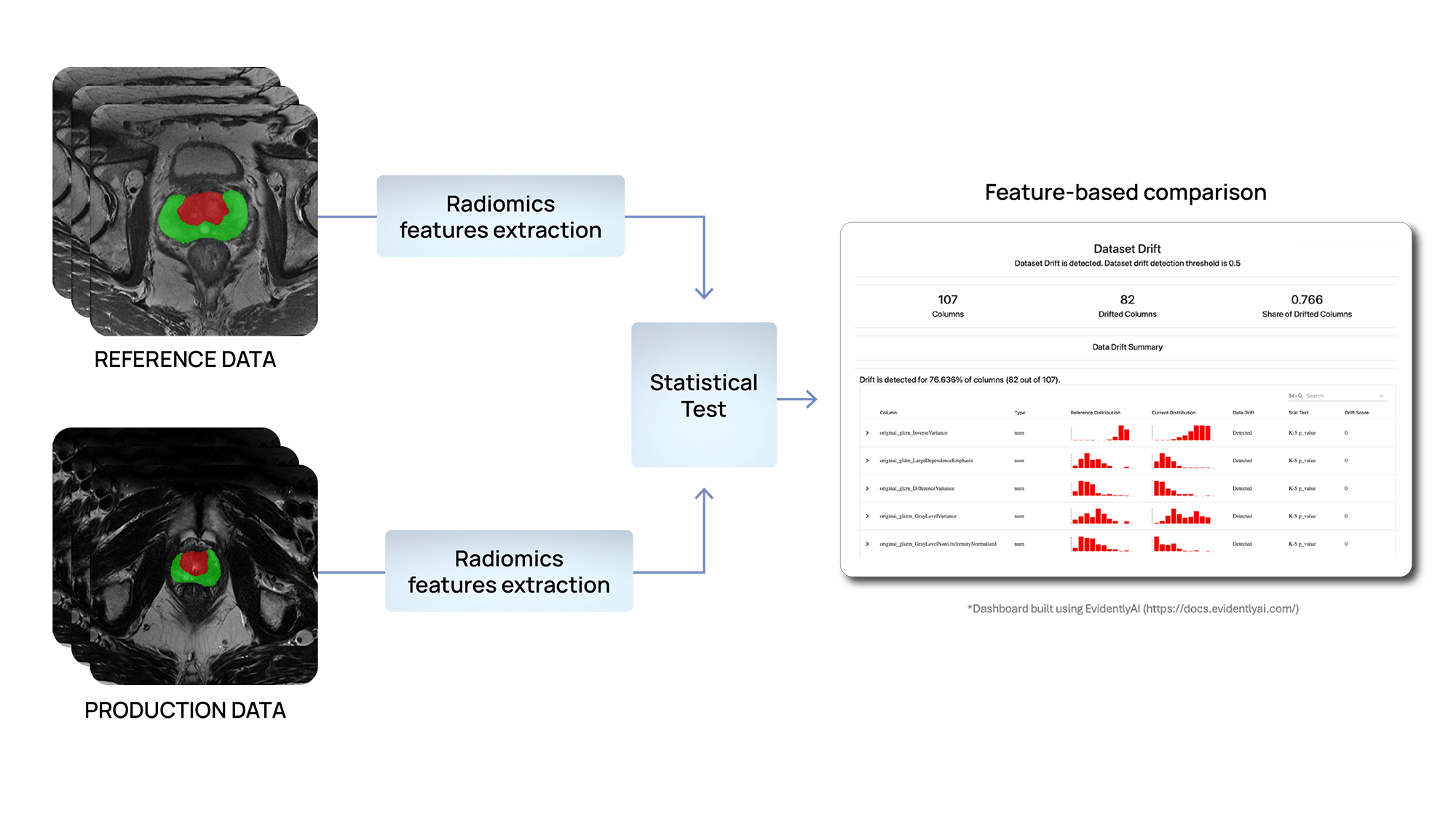
Figure 3 - Détection de dérive de données à l'aide des fonctionnalités radiomiques