¿Alguna vez ha para una degradación en el rendimiento of ¿Tus modelos de IA?
El desarrollo de un modelo de IA implica, en imágenes médicas como en cualquier otro campo, un proceso integral con varios pasos críticos. Comienza con Recopilación y preparación de datos, asegurando que los datos estén limpios, sean relevantes y adecuados para el análisis. A continuación, la fase de diseño implica creando la arquitectura del modelo inicial y seleccionando algoritmos apropiados. Se realizan múltiples experimentos y validaciones para probar distintas configuraciones y enfoques. Estos experimentos ayudan a refinar el modelo, optimizar sus parámetros y mejorar su precisión y rendimiento. Este proceso iterativo continúa hasta que se obtiene el mejor rendimiento. AI Se identifica el modelo. Luego, este modelo se selecciona para integrarlo en una solución final, lista para implementarse y utilizarse en aplicaciones prácticas.
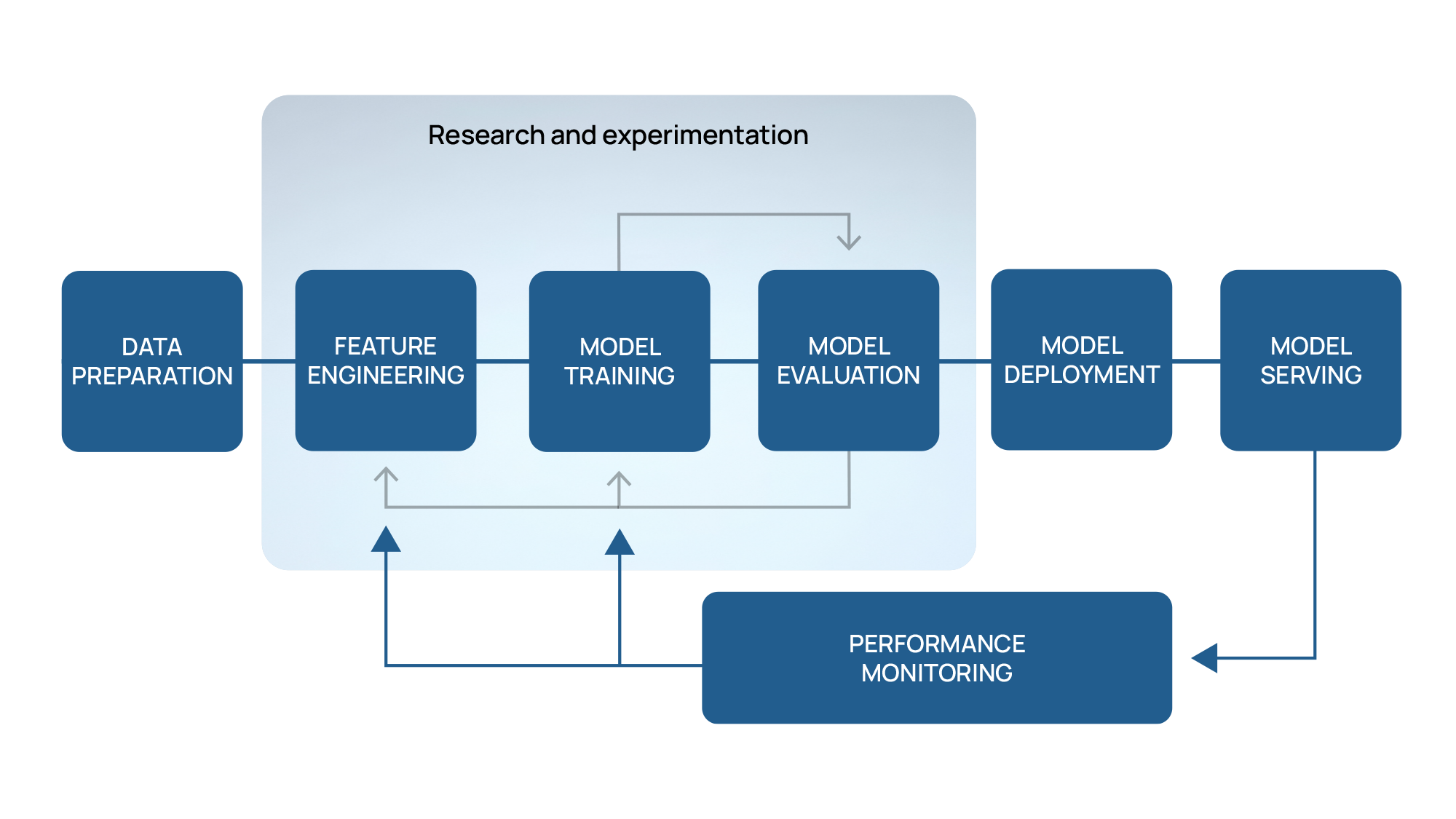
Figurae 1 – Flujo de trabajo de desarrollo de modelos de IA
Sin embargo, el flujo de trabajo de IA no debería concluir una vez que el modelo se implementa en producción. Con el tiempo, Los modelos en producción sufrirán una pérdida de su poder predictivo, un fenómeno conocido como deriva del modelo. Esta disminución es resultado de cambios continuos en los datos utilizados como entrada para los modelos. Ejemplos de estos cambios en el campo de las imágenes médicas pueden surgir de nuevos avances en tecnologías de imágenes o alteraciones en los protocolos de adquisición. En consecuencia, los modelos encuentran datos con los que necesitan ser entrenados, lo que genera una posible disminución en la precisión de sus predicciones médicas.
Por lo tanto, es crucial monitorear continuamente el desempeño de los modelos de IA para identificar dichos problemas y desarrollar estrategias para mitigarlos. La deriva del modelo se puede clasificar en dos tipos principales:
Deriva del concepto
Se produce una desviación del concepto cuando cambian los patrones aprendidos por el modelo a partir de los datos de entrenamiento/prueba, Esto puede dar lugar a patrones nuevos e inéditos en los datos de producción. Por ejemplo, en el campo de las imágenes médicas, esto puede ocurrir con la aparición de nuevas enfermedades o tratamientos. Al comienzo de la pandemia de COVID-19, los modelos de IA entrenados inicialmente para identificar anomalías en las radiografías de tórax no pudieron detectar anomalías relacionadas con la COVID-19. Este es un claro ejemplo de deriva conceptual.
Covariable o deriva de datos
Este tipo de deriva ocurre cuando la distribución de características en los datos de entrenamiento/prueba difiere de la de los datos de predicción. La deriva de covariable se puede dividir en deriva de entrada y deriva de salida.
Desviación de entrada
Esto implica cambios en los datos de entrada, como alteraciones en servicios imágenes o características causadas por modificaciones en los escáneres. Esto puede afectar a los modelos de IA, ya que los modelos entrenados con imágenes de escáneres actuales podrían no funcionar bien con imágenes de escáneres futuros, si se utilizan nuevas reconstrucciones de imágenes o nuevas técnicas de contraste.
Deriva de salida
Esto ocurre cuando hay cambios en la distribución de los resultados del modelo, que pueden ser resultado de cambios en las directrices de presentación de informes.
Un ejemplo de este problema podría ser un modelo de imágenes médicas entrenado para clasificar las etapas de tumores primarios en el cáncer de pulmón. Supongamos que el modelo se desarrolló utilizando datos clasificados según la 7.ª edición de la estadificación TNM del cáncer de pulmón. Si los nuevos datos en producción se adhieren a las pautas de la 8.ª edición, la distribución de resultados del modelo cambiará. Este cambio puede provocar una disminución del rendimiento, ya que el modelo puede dejar de alinearse con los estándares actualizados, lo que puede dar lugar a imprecisiones en la estadificación del tumor primario.

Figurae 2 – Concepto y deriva de datos
Detección de la desviación del modelo
Hay dos estrategias principales para detectar la desviación del modelo, dependiendo de la disponibilidad de datos reales (valores reales):
Detección de deriva supervisada
Cuando la verdad fundamental esté disponible algún tiempo después de las predicciones del modelo, se puede utilizar para comparar con estas predicciones. Utilizando las mismas estrategias de validación empleadas durante el desarrollo y la selección del modelo. Si las métricas obtenidas en producción son significativamente peores que las de la fase de validación, el modelo está experimentando una desviación.
Detección de deriva sin supervisión
Se requiere un enfoque más desafiante en escenarios donde la verdad fundamental no está disponibleNos centraremos aquí en este escenario, que es el más común en aplicaciones del mundo real.
Varios métodos para detectar la deriva de forma no supervisada varían según el tipo de datos, el algoritmo y si utilizan predicciones de entrada o de salida.
- Enfoques basados en pruebas estadísticas
Uno de los métodos más utilizados implica pruebas estadísticas que comparan distribuciones de datos.Estas pruebas funcionan bajo la hipótesis de que si existen disparidades estadísticas significativas entre los datos de referencia (utilizados para entrenamiento y pruebas) y los datos de análisis (empleados en producción), no podemos asumir que el modelo producirá resultados similares en ambos conjuntos de datos.
Normalmente, estas pruebas comparan variables numéricas o categóricas calculando ciertas métricas para medir la divergencia entre los dos conjuntos de datos. Si estas diferencias superan un umbral especificado, el algoritmo considera que existe una deriva. Algunos ejemplos de estos métodos son los siguientes: Prueba de Kolmogorov-Smirnov de dos muestras, prueba de chi-cuadrado, Distancia de Wassertein or Divergencia de Kullback-Leibler.
- Enfoques basados en la clasificación
Otro enfoque implica algoritmos de IA para detectar diferencias entre conjuntos de datos, específicamente entre conjuntos de datos de referencia y de producción. Un ejemplo es el clasificador de dominios. En este método, se entrena un modelo utilizando un subconjunto de datos de referencia y de producción. Si el modelo puede determinar con precisión si los nuevos puntos de datos pertenecen al dominio de referencia o de producción, esto indica que existen diferencias significativas entre los conjuntos de datos. Esto implica que los datos en producción son diferentes del conjunto de datos de referencia, lo que potencialmente afecta el desempeño predictivo del modelo.
- Enfoques basados en la incertidumbre
Otros métodos aprovechan la incertidumbre del modelo en la producción para detectar desviaciones.La incertidumbre del modelo mide qué tan seguro está el modelo acerca de sus predicciones y puede monitorearse durante la producción. Si el modelo comienza a mostrar mayor incertidumbre en sus predicciones, podría indicar que características específicas de los datos de producción están reduciendo la confianza del modelo. Esto podría indicar una posible disminución en el rendimiento.
Monitoreo del desempeño en Quibim
In QuibimReconocemos la importancia de monitorear el desempeño de nuestros modelos en producción y detectar disminuciones en la precisión predictiva lo antes posible. Investigamos continuamente los mejores enfoques para cada uno de nuestros modelos en producción.
En nuestros productos integramos un sistema de monitorización como estrategia de vigilancia post-comercialización, con el fin de detectar, lo antes posible, potenciales focos de deriva y minimizarlos, mejorando la experiencia del cliente. Adicionalmente, Estamos a la vanguardia en el desarrollo de herramientas para monitorear modelos de producción a través de Proyectos financiados con fondos europeos San Pancho ProCancer-I y el RadioVal. En estos proyectos estamos desarrollando herramientas que incorporan múltiples métodos para detectar desviaciones en los modelos de IA en producción para diferentes casos de uso.
Estamos empleando métodos basados en pruebas estadísticas para detectar cambios en la distribución de los datos de entrada.En concreto, estamos desarrollando soluciones para identificar diferencias dentro de las características radiómicas extraídas a nivel de órgano o de lesión en diferentes casos de uso.
In RadioValLas características radiómicas se utilizan para predecir la respuesta de los pacientes a la quimioterapia neoadyuvante. De manera similar, en ProCancer-I, Se están desarrollando modelos predictivos basados en características radiómicas para el diagnóstico temprano, la asignación de tratamiento y la predicción de la respuesta, y el seguimiento de pacientes con cáncer de próstata. Basándose en el supuesto de que las distribuciones de estas características deben permanecer consistentes entre los datos de referencia y de producción, Si se encuentran inconsistencias, puede indicar que el modelo está haciendo predicciones sobre datos diferentes a aquellos con los que fue entrenado y validado, lo que podría afectar su desempeño.
Se ha desarrollado un enfoque complementario para abordar la desviación de los datos de entrada. En este segundo escenario, nos centramos directamente en los datos de imágenes. En ProCAncer-I utilizamos enfoques que implican el empleo de codificadores automáticos, algoritmos de IA que se pueden usar para extraer características profundas de las imágenes.Los modelos de IA utilizan estas características profundas, representadas como valores numéricos, para realizar tareas como la reconstrucción de imágenes. Sin embargo, también se pueden utilizar para comparar distribuciones de datos. Si las características profundas de los datos de entrenamiento y prueba son significativamente diferentes de las extraídas de los datos de producción, esto puede ser un indicio de una desviación del modelo.
Finalmente, Estamos incorporando métodos adicionales para detectar la deriva del objetivo en nuestros modelos de clasificación. Estos métodos comparan la distribución de los resultados del modelo entre los datos de referencia y los datos de producción utilizando también pruebas estadísticas. Si se detectan cambios significativos, es necesario realizar un análisis más profundo de los datos para excluir la posibilidad de una disminución en el rendimiento de clasificación del modelo en la producción.
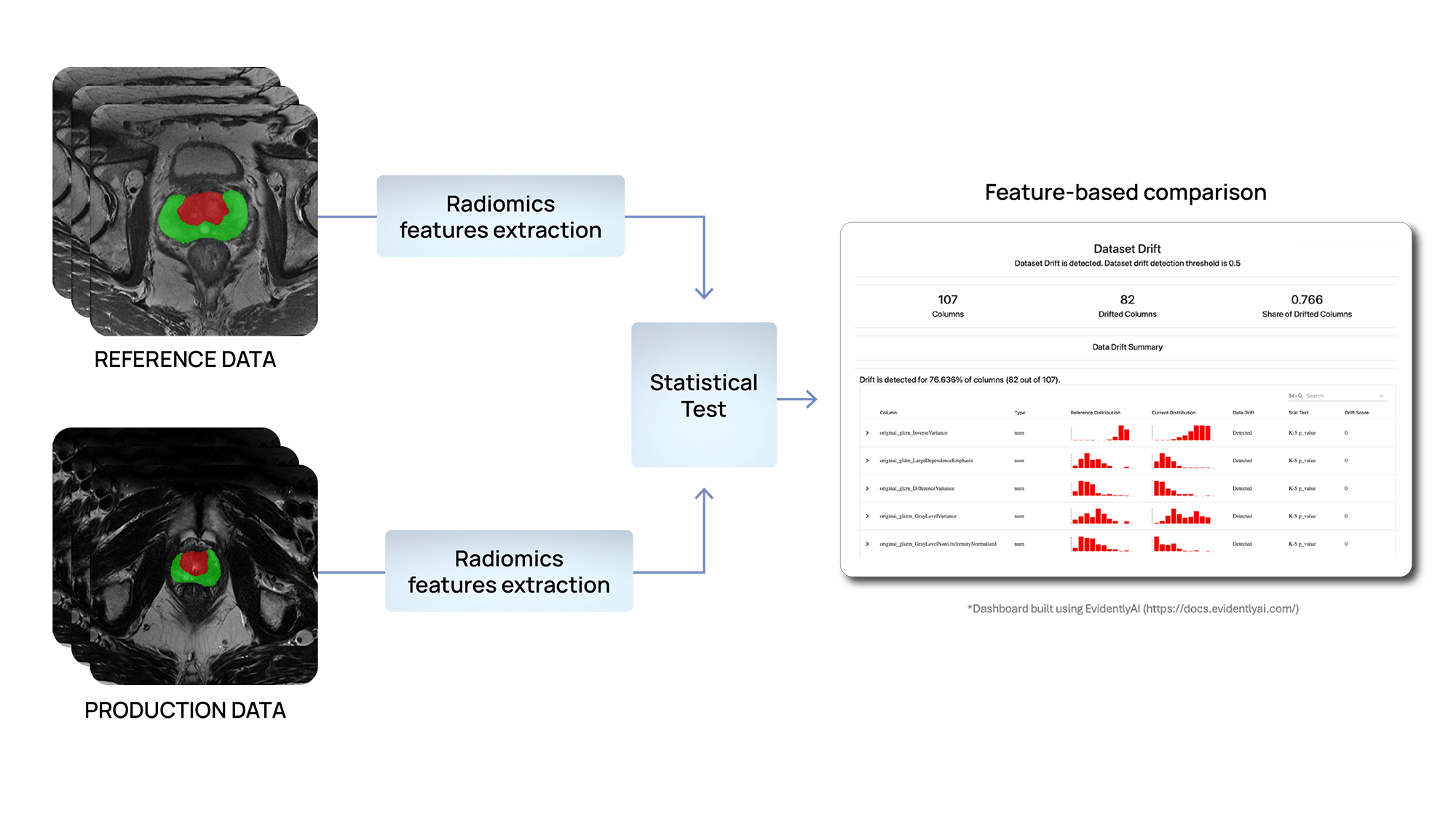
Figura 3 - Detección de deriva de datos mediante funciones radiómicas